
自己衝突のある布のシミュレーションを作りました。Works から見られます。Neort にも置いてあります。こっちはメイン部分のソースコードも見られます。
布のシミュレーション手法自体は色々な所で解説されていると思うので、自己衝突検出に利用した Spatial Hashing の説明を書いておきます。
布自体は下の画像のようなワイヤーフレームで構成されており、質点とそれらを結ぶバネ(のような何か)でモデル化してあります。
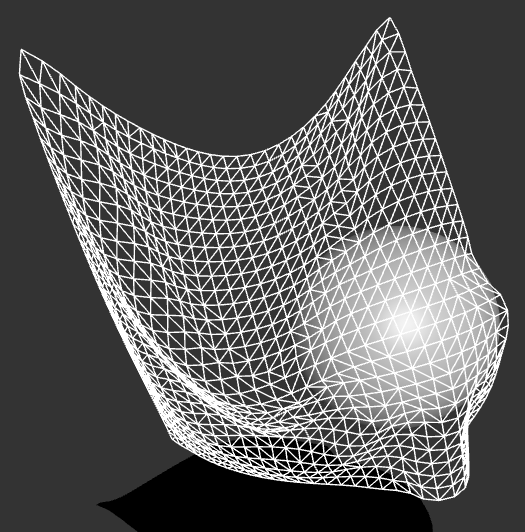
自己衝突を計算する際は、本当は布を構成する各頂点と三角形の衝突検出を行う必要がありますが、今回は計算と実装を簡単にするために質点を球と見なし、球同士の衝突を計算することで自己衝突を計算しています。この方法は薄い布を再現できない、表面がゴツゴツするなどのデメリットがありますが、それなりに細かいメッシュで構成されていて、とりあえずすり抜けなければいいや!みたいな場合には結構使えます。
今回のように
- 大量のパーティクルが
- 同じ半径をもって
衝突する場合、均一格子 (Uniform Grid) による空間分割手法が衝突検出手法に適しています。計算の流れとしては、一辺の長さが「粒子が衝突を起こす距離」に設定した空間を覆う格子を用意し、
- 各粒子が存在する格子に粒子を「登録」する
- ある粒子と衝突している粒子を調べるために、「その粒子が存在している格子」と「その格子に隣接している格子」に登録されている粒子との衝突判定を行う
という流れになります。粒子が N 個存在する場合、全探索による判定(全ての粒子ペアに対して衝突判定を行う)だと O(N^2) の計算時間がかかりますが、粒子が十分にばらけている場合は、均一格子を用いることで O(N) まで計算量が落ちます(それはそうですが、そもそも粒子が密集していたらどうあがいても O(N^2) の計算時間がかかります)。
その他の広域衝突検出 (Broad-Phase Collision Detection) 手法と比べると、Octree や Bounding Volume Hierarchy などの階層構造を用いるものが O(N\log N)、Sweep and Prune などのソートを用いるものが同様に O(N\log N) となるので、O(N) 時間で判定を行える均一格子を用いた手法は非常に高速ということになります。ソートアルゴリズムで例えるとバケツソートや基数ソートなんかに近い手法になります。
で、この均一格子を用いた手法ですが、実装の仕方でいくつかの種類に分けられます。
一番簡単なのが、格子を丸ごと多次元配列的にメモリに確保しておく方法で、各格子に登録されている粒子のリストを持たせることで特に難しいこともなく実装できます。この方法の難しいところは、「粒子が動きうる空間を前もって把握しておく必要がある点」「広い空間で計算を行う場合に膨大なメモリを使用する点」あたりです。特に3次元では次元の呪いを受けて大変なことになります。
他に、もう少しフレキシブルで GPU 向きな方法として、各粒子が存在する格子のインデックスを求める → インデックスに従い粒子をソートする → 格子のインデックスから粒子のインデックスを逆算する配列を作る という方法がありますが、今回は割愛します(この場合のソートには基数ソートが使われることが多いようです)。
そして、空間の疎性を利用した Spatial Hashing があります。
多次元配列的に格子をメモリに確保する方法の無駄な点として、(特に3次元では)ほとんどの格子が空であるという状況が発生しがちな点が挙げられます。我々は虚無のために大量のメモリを確保していたのです。なんともったいない。
ということで、スカスカな格子を圧縮してやろうという発想に至ります。この用途にピッタリなのがハッシュ関数です。各格子のインデックスを適当なハッシュ関数に通すことにより、1次元の整数値が得られます。さらに、この整数値を適当な定数 M で割った余りを求めることで、各格子に対して 0 以上 M 未満の整数値が得られます。この整数値を格子の圧縮された添え字とします。また、ある格子に対して、その格子の圧縮された添え字に対応する格子(注:この格子は要素数 M の1次元配列に確保されており、元の格子とは異なるものです)を格子の圧縮先と呼ぶことにします。
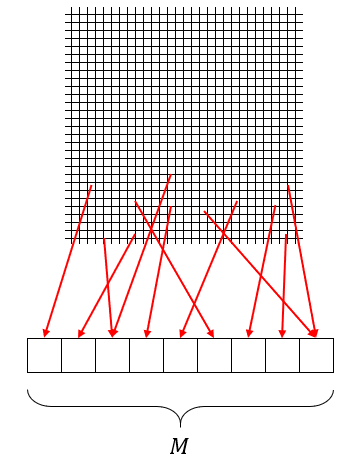
格子を圧縮するイメージ
そして、先ほど出てきた計算方法を次のように読み替えます。
- 各粒子が存在する格子の圧縮先に粒子を「登録」する
- ある粒子と衝突している粒子を調べるために、「その粒子が存在している格子の圧縮先」と「その格子に隣接している格子の圧縮先」に登録されている粒子との衝突判定を行う
参照・操作の先が格子そのものではなく格子の圧縮先に置き換わっただけです。当然ながら複数の格子が同じ圧縮先に圧縮されることもありますが(ハッシュ関数の衝突)、衝突検出の性質上、余分な衝突判定を行うことは計算時間が増えることを除いて何ら問題がないことに注意します。定数 M を増やせばハッシュ衝突の可能性は下がりますが、メモリの使用量は増えることになります。Spatial Hashing を利用することで、「使用メモリ極振り」の状態から「問題に合わせた使用メモリと計算速度のトレードオフ」を手に入れることができたというわけです。
さらに嬉しい恩恵として、ハッシュ関数による圧縮の結果、格子が存在する場所に関係なく圧縮後の添え字が常に 0 以上 M 未満の範囲内となるので、もはや「粒子が動きうる空間を前もって把握しておく必要はない」ことになります。どこまで粒子が飛んでいこうが、飛んで行った先できちんと衝突検出が行われます。しかも、計算時間は O(N) のままです。
今回実装したのはこれが初めてだったのですが、非常に便利な手法なので今後も活用していきたいと思います。